Designing Tomorrow's Algorithms on Today's Architectures: a Case Study with Stencil Computations Using AMD 3D V-Cache™ Technology
About
Regular stencil computations constitute the main core kernel in many temporally explicit approaches for structured grid finite-difference, finite-volume, and finite-element discretizations of partial differential equation conservation laws.
For various blocking dimensions, the Spatial Blocking (SB) approach enables data reuse within multiple cache levels. However, the straightforward generalization of SB to manycore architectures, with each core owning an exclusive share of cache may leave performance on the table. The next two figures show the typical 25-point 3D star stencil used in seismic imaging to solve the 3D acoustic wave equation across the 3D domain tiled with cubes, as computed with SB.
 |
 |
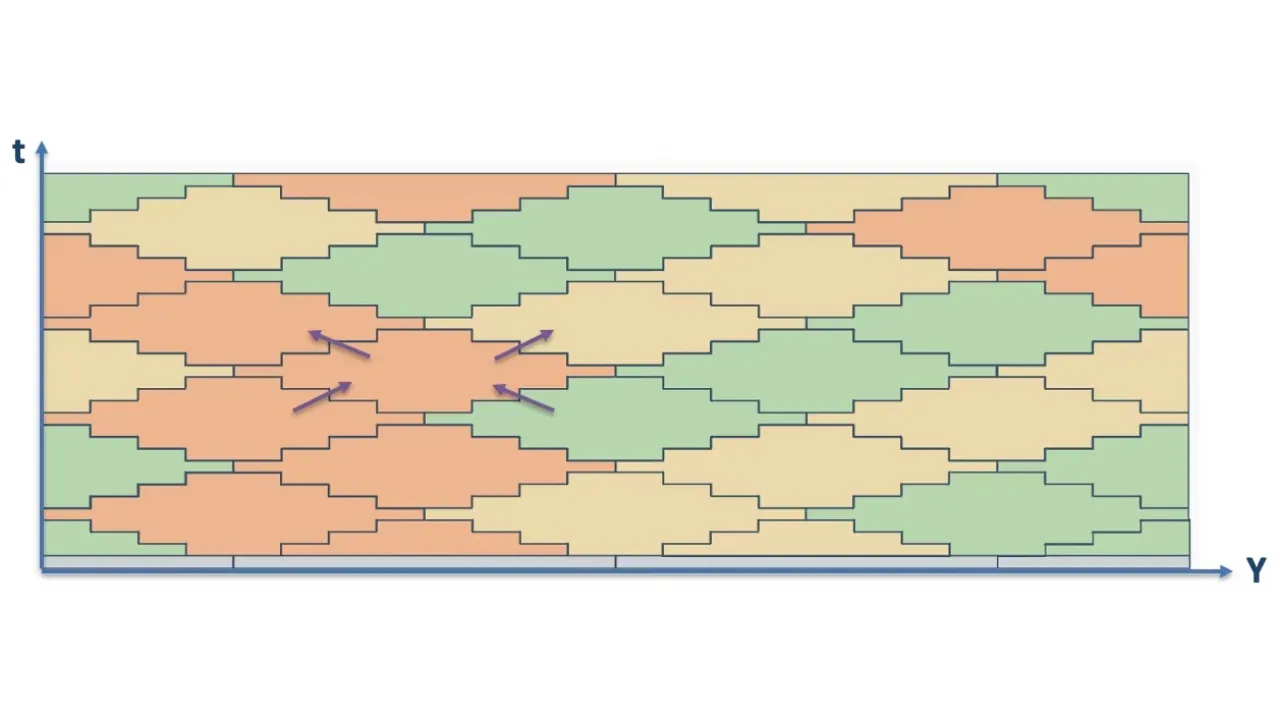
The Temporal Blocking (TB) method improves data locality further by adding another level of blocking along the time dimension via a diamond tiling mechanism, as shown in the two figures below. Introduced in GIRIH, the Multicore Wavefront Diamond blocking (MWD) method [1, 2] optimizes practically relevant stencil algorithms by combining the concepts of diamond tiling and multi-core aware wavefront temporal blocking, leading to significant increase in data reuse and locality.


Recent studies [3,4] show the impact of MWD on the performance of seismic applications and highlights its performance superiority versus SB on two-socket 64-core AMD Epyc Rome. The Last Level Cache (LLC) shared among cores permits to reduce memory access across successive iterations. With the latest AMD Epyc Milan-X architecture, we notice a 3X increase in LLC capacity compared to Rome/Milan, as shown in the next figure with AMD Milan-X Cache Hierarchy.

We evaluate the performance of MWD on a variety of multicore x86 architectures and demonstrate performance superiority over SB. In particular, our MWD approach on Milan-X reaches up to 3.1X performance speedup against SB on Milan (or Milan-X).

We further assess the obtained performance of our MWD implementation on Epyc Milan and Milan-X using the roofline model. The gap between the two dots of L3 and DRAM-MWD on Milan widens on Milan-X and shows how MWD decouples from main memory.

|

|
To summarize, MWD works best against SB on hardware with a wide bandwidth gap between LLC and main memory. MWD achieves high performance in presence of large shared LLC shared among several cores and is agnostic to main memory technology (e.g., HBM). This work will be presented at SC22 during the poster session.
References:
Software: GIRIH can be found at https://github.com/ecrc/girih.
[1] Malas T., Hager G., Ltaief H., Stengel H., Wellein G. and Keyes D. (2015) Multicore Optimized Wavefront Diamond Blocking for Optimizing Stencil Updates. SIAM J. Sci. Comput. 37(4): 439–464.
[2] Malas T., Hager G., Ltaief H. and Keyes D. (2017) Multidimensional Intratile Parallelization for Memory-Starved Stencil Computations. ACM Trans. Par. Comput. 4(3): 12:1–12:32.
[3] Akbudak K., Ltaief H., Etienne V., Abdelkhalak R., Tonellot T., and Keyes D. (2020). Asynchronous computations for solving the acoustic wave propagation equation. The International Journal of High Performance Computing Applications, 34(4), 377–393.
[4] Qu L., Abdelkhalek R., Said I., Ltaief H. and Keyes D. (accepted for publication, 2022) Exploiting Temporal Data Reuse and Asynchrony in the Reverse Time Migration, Int. J. High Perf. Comput. Appl.
Related People
Related Researchers
Long Qu
- Research Scientist, Hierarchical Computations on Manycore Architectures

Hatem Ltaief
- Principal Research Scientist, Applied Mathematics and Computational Science
